131 1300 0010
为了提升计算基础设施的性能,并紧跟数据分析与 AI 不断攀升的需求,众多企业将硬件加速视为主要的解决方案。在大多数情况下,先进的可编程硬件(主要是指 GPU 和 FPGA)是加速的主要方式。通过使用这种先进的硬件,企业正在赢得计算优势;然而,对于编程难度,他们仍然存在合理的担忧。
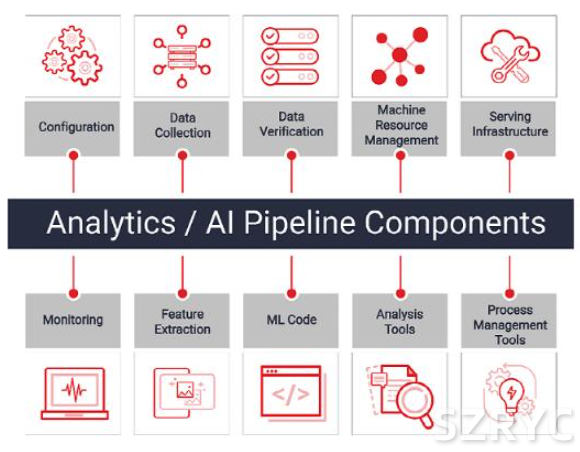
图 1:分析/AI 流水线组件
硬件制造商正在将加速方法应用于计算存储,这是专门设计用于包含内嵌计算元素的存储。这种方法已经被证明可以为分析和 AI 应用提供优异的性能(图 1)。使用或者不使用机器学习辅助的分析以及验证,都可以借助计算存储器件进行加速。这些器件提供了一个关键的优势,使得成本高昂的计算被卸载到存储器件上,而不必在服务器 CPU 上完成。与标准的存储/CPU 方法相比,通过计算存储获得的优势包括:
1. 借助应用专用编程定制可编程硬件,获得更高性能
2. 将计算任务从服务器卸载到存储器件,释放 CPU 资源
3. 数据与计算共址,降低数据传输需求
这种新颖的方法前景光明。不过,您应根据具体用例评估这种方法,考量性能、成本、功耗和易用性。性价比和单位功耗性能在选择加速硬件评估时,占据主要比率。在本文中,我们将研讨单位功耗性能(另一篇文章则专门研讨性价比)。
计算存储功耗比较
3种系统
在这个场景中,我们将比较以 CSV 数据读取用例为主的三种工具:英伟达 GPUDirect 存储 和RAPIDS存储,以及基于赛灵思技术的三星 SmartSSD 存储。CSV 读取在计算密集型流水线中起着重要的作用(参见图 1)。
在下文中,我们将性能定义成 CSV 的处理速率,或处理“带宽”。我们先快速回顾一下三种系统的运行方式。
英伟达 GPUDirect 存储
·端到端满足分析和 AI 需求
·将 GPU 用作计算单元,紧贴基于 NVMe 的存储器件布局 (GPUDirect)
·使用 CUDA 进行编程 (RAPIDS)
英伟达用其 CSV 数据读取技术衡量相对于标准 SSD 的性能提升。结果如图 1 所示。使用 1 到 8 个加速器时,对应的吞吐量是 4 到 23GB/s。
三星 SmartSSD 驱动器
·将赛灵思 FPGA 用作计算单元
·与存储逻辑内嵌驻留在同一个内部 PCIe 互联上
·通过编程在存储平台上开展运算
赛灵思数据分析解决方案合作伙伴 Bigstream 与三星合作,为 Apache Spark 设计加速器,包括用于 CSV 和 Parquet 处理的 IP。SmartSSD 的测试使用单机模式的 CSV 解析引擎,以便开展比较。结果如图 2 所示,使用 1 到 12 个加速器时,对应的吞吐量是 4 到 23GB/s,同时也给出英伟达的结果(使用 1 到 8 个加速器)。请注意,本讨论中的所有结果都按 x 轴上的加速器数量进行参数化。
这些结果令人振奋,但在选择您的解决方案时,请务必将功耗情况纳入考虑。
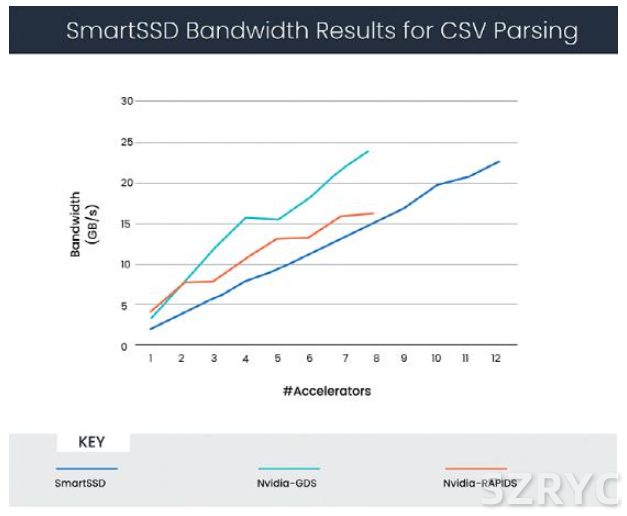
图 2:SmartSSD 驱动器的 CSV 解析性能结果
单位功耗性能比较
图 3 显示了将功耗考虑在内后的分析结果。它们代表单位功耗达到的性能水平,根据上述讨论中引用的相关材料,给出了以下假设:
·Tesla V100 GPU:最大功耗 200 瓦
·SmartSSD 驱动器 FPGA:最大功耗 30 瓦
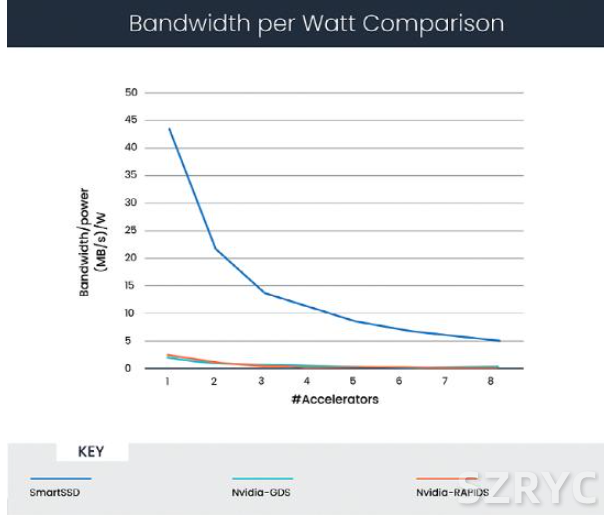
图 3:CSV 解析的每瓦功耗带宽比较
在这个场景下,计算表明,在全部使用 8 个加速器的情况下,SmartSSD 的单位功耗性能比 GPUDirect Storage 高 25 倍。
FPGA 与 GPU 对比:有关单位功耗性能的最终思考
计算存储的优势在于能增强数据分析和 AI 应用的性能。然而,要让这种方法具备可实际部署的能力和实用性,就必须在评估时将功耗纳入考虑。
针对用于 CSV 数据解析的两种不同的计算存储方法,我们已经提出按功耗参数化的吞吐量性能曲线。结果显示,在使用相似数量的加速器进行比较时,SmartSSD 驱动器的单位功耗性能优于 GPUDirect存储方法。
GPUDirect 是英伟达通过 NVIDIA DGX-2 应用平台提供的研究系统。
三星 SmartSSD 驱动器是一种可部署的量产型 PCIe 可插拔平台,现在已经通过赛灵思及分销商供货。
如需了解更多信息,请查看:
· 有关 Bigstream 与 SmartSSD 计算存储器件结合使用,加速大数据和数据分析的电子书。
· Bigstream 硬件加速 Apache Spark解决方案。
· 有关使用三星 SmartSSD 驱动器给工作负载带来优势的 三星 SmartSSD 页面。

