131 1300 0010
在这个移动设备成为主要计算平台的大时代,稍微关注行业的人都听说过ARM,该公司作为技术推动者,提供各种处理器架构以及核心参考设计,基本上已成为当今所有移动设备的动力之源,并在过去的5~7年里,引领着智能手机和平板电脑SoC性能的飞速发展。
ARM的雄心远远超出了移动和嵌入式设备领域。从商业意义上来看,服务器和相关基础设施等高端领域有着更大的利润空间,对于像ARM这样的公司来说,这是一个非常有利可图的市场。
不过,尽管ARM在移动和嵌入式设备领域取得了巨大的成功,但迄今为止始终未能触及更高性能产品的领域。
虽然在过去的十年中,许多关于“ARM将掀起服务器和基础架构市场革命”的预言层出不穷,也有不同的供应商试图实现这一目标,然而前几代产品并没有获得成功,ARM的服务器生态系统也遇到了相当大的困难。

服务器领域,多事之秋
去年年中,全新的Cortex A76架构横空出世,ARM对其寄予厚望,以至于随后公开分享了未来三年的CPU路线图,并宣布将在PC笔记本电脑领域与Intel展开正面竞争。尽管骁龙8CX等产品的上市还需要等待很久,但外媒Anandtech已经拿到了首批搭载Cortex A76的移动设备,并验证了ARM的所有性能和效率声明。
最近,ARM又发布了新星架构Neoverse,并希望通过新一代处理器设计大幅提升其性能,并提高在服务器和基础设施领域的竞争力。
这些新架构对ARM来说都很重要,它们代表了市场的一个转折点:ARM处理器的性能表现已经接近了Intel和AMD处理器,且ARM有信心保持每年25~30%的性能提升,大幅超越Intel和AMD的迭代幅度。

过去几个月对于ARM服务器生态系统来说是非常值得欣喜的。在去年的Hotchips大会上,富士通展示了全新的A64FX高性能计算处理器,不仅代表了公司从SPARC架构体系转向ARMv8架构体系,还提供了第一款在ARM架构中实现新SVE(可扩展矢量扩展)的芯片。
Cavium的ThunderX2也取得了令人印象深刻的性能飞跃,使其新处理器成为首批能够与Intel和AMD竞争的处理器。
前阵子,我们又看到了华为推出的全新鲲鹏920服务器芯片,该芯片有望成为业界性能最高的ARM服务器CPU。
上述三种产品之间最大的共性是,每种产品都代表了各供应商在实施基于ARMv8架构许可的定制微体系结构方面所做的努力。这实际上引出了一个问题:ARM自己的服务器和基础设施市场计划是什么?
此次,我们将详细介绍Neoverse N1这个新平台,它们将成为未来几年ARM的基础设施战略的核心,并初步实现服务器生态系统。
Neoverse N1 CPU:无妥协性能
Neoverse N1平台的核心是Neoverse N1 CPU,即CPU品牌与平台品牌有相同的命名。ARM所描述的平台不仅是CPU核心,还包括周围的互连IP,使整个系统可以扩展到多核系统。
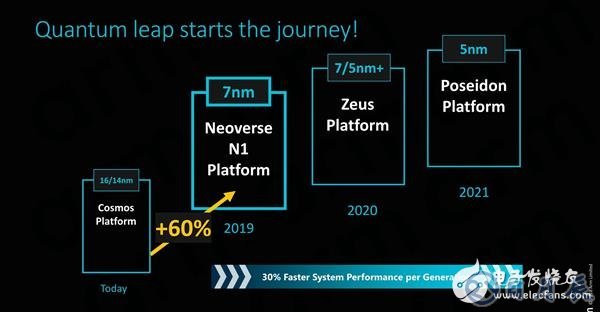
Neoverse N1平台和CPU代表了ARM首款专为服务器和基础设施市场设计的专用计算IP。这是对过去IP产品的重大改变,其中将为消费产品和行业解决方案提供相同的CPU IP。这些IP家族之间的新技术区别促使ARM为新的基础架构目标产品采用新的营销名称,因此Neoverse品牌诞生,与面向消费者的Cortex CPU品牌区别开来。
Neoverse N1平台代表了ARM奥斯汀设计中心“第二代奥斯汀家族”的第一次迭代。Neoverse N1原名为“战神”,代表了与Cortex A76相对应的服务器处理器核心。同时,奥斯汀团队可能已经完成了第二次迭代所需的Zeus架构的设计工作;随后Poseidon架构将成为这一家族的最后一次迭代,然后将接力棒传递给由法国的索菲亚团队设计的下一个架构家族。
由于Neoverse N1是Cortex A76架构的兄弟,两款核心之间自然有很多相似之处。我们去年曾详细介绍了Cortex A76架构,这些设计细节也同样适用于Neoverse N1,二者仅在适应基础设施用例方面有些差异。

就高层设计目标而言,ARM的目标似乎相当直接:创建一个毫不妥协的架构,并成为未来几年内可重复使用的基础。
特别值得一提的是,我们从Cortex A76上可以看出,ARM正在调整架构设计,使其能够在基础设施部署中以最高频率运行。这与Intel和AMD在服务器CPU上采用的策略形成了鲜明的对比。
ARM在服务器CPU上的优势在于可以同时优化性能、功耗和面积,而Intel和AMD不得不在这些指标中做出妥协,使其产品虽然与对应的消费级产品有着类似的架构,但频率往往非常有限,这取决于给定的SKU针对的是哪个细分市场。
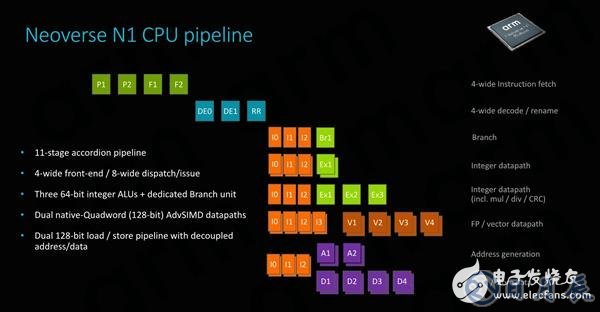
Neoverse N1的流水线结构与Cortex A76相同,均为11级短流水线设计,前端都是4宽的读取/解码器。ARM将其称为“手风琴”管道,因为根据指令长度不同,它可以在延迟敏感的情况下将第二预测阶段与第一获取阶段重叠,将调度阶段与第一发布阶段重叠,将流水线长度减少到9级。
执行后端也看起来与Cortex A76完全相同,拥有2个处理加减运算的简单ALU、1个处理乘除运算的复杂ALU,以及2个处理向量和浮点运算的全宽128位SIMD流水线。
数据吞吐量是处理器架构的一项重要指标,ARM为Neoverse N1设计了两个128位加载/存储单元,能够维持足够的带宽来提供和服务执行流水线。
架构前端与Cortex A76同样非常相似,大容量的L1和L2具有低延迟访问性能。这里的ARM还采用了业界公知的一些最大的分支目标和方向预测缓冲器,尝试保持数据流经核心,并最小化分支预测和缓存命中失败的概率来提高性能。

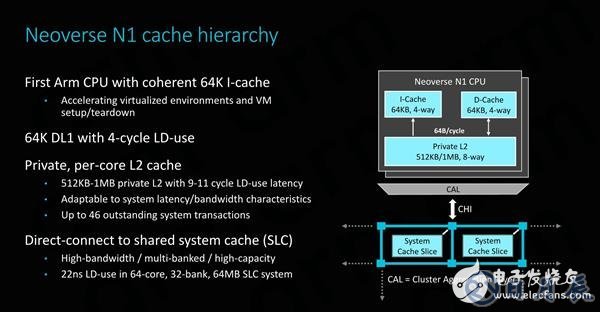
在缓存层次结构方面,Neoverse N1与Cortex A76相差很大。二者的L1缓存容量均为64KB,读取延迟为4个周期,但是Neoverse N1上最大的不同在于缓存是完全一致的。
需要注意的是,硬件I-cache的一致性并不是ISA所要求的,到目前为止,通常都是通过软件维护操作来完成的。
为N1实现硬件一致性对ARM来说非常重要,因为它极大地提高了性能并简化了虚拟环境的实现,如果ARM想要在超大规模客户中具有竞争力,就必须具备这些特性。拥有I-Cache的一致性被认为是一个关键的支持因素,可以使系统具有非常大的内核计数,ARM表示16核以上的系统都必须具备这一特性。
L2缓存可选择512KB或1MB的配置,使用512KB配置时与Cortex A76基本相同,而1MB缓存则可以应对内存占用更大的应用程序。不过,将L2缓存加倍到1MB并不是没有代价的,这会让缓存的延迟增加2个周期,达到11个周期的负载使用延迟。
Neoverse N1与Cortex A76的一个很大的区别在于,在进行大尺度缓存操作时,Neoverse N1不会去寻找集群,而是会使用mash互联的方式。
如图所示,该连接首先通过一个CAL或组件聚合层。每个CAL最多支持两个接口,这就是为什么我们在每个“集群”中只能看到两个CPU(它本身并不是真正的集群)。然后CAL连接到网格的XP(交叉点),它本质上是网络的交换机/路由器组件。每个XP都有两个可用端口;在ARM参考设计示例中,第二个端口连接一个系统级缓存。
在64核系统搭配2MB系统级缓存的示例系统中,整个64MB缓存的平均负载使用延迟为22ns。ARM给出的延迟数据是纳秒数而不是周期数的原因是系统级缓存和mesh运行在与CPU异步的频率上,通常是内核频率的2/3左右。
直接连接是Neoverse N1和CMN-600的一个整体特征。这个特性只存在于这个平台上,而在Cortex架构上是不可能实现的。本质上,它删除了DSU的所有L3和探听过滤器逻辑,而是直接将CPU内核连接到CMN的CHI接口。因此,内存控制器和CPU核心之间的通信本质上只需要通过一个中间层,即mash网络本身。
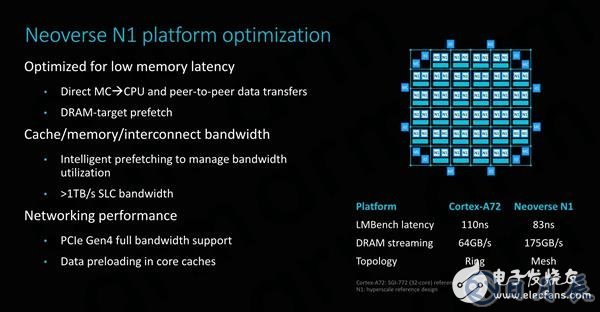
直接从内存控制器向CPU数据传输可能有点难以解释,当CPU向内存控制器发出数据请求时,它能够立即同时首先向其发送“预取”类型请求,同时通过mesh网络中XP主节点的探听过滤器正常传输命令,然后将请求路由到内存控制器。因此,内存控制器将提前知道请求的到来,并且已经开始获取数据,从而隐藏部分有效的内存延迟,而不是整个传输按串行顺序进行。
预取对整个系统的性能非常重要,智能管理数据预取可以有效优化系统级带宽。据说在具有64核心和8个DDR4 3200内存通道的Neoverse N1参考系统中,可以实现高达175GB/s的内存带宽。ARM还公布了延迟数据,但ARM的数据表示LMBench数据,同时配置了256MB测试深度的2MB大页面。选择大页面可以减少TLB的遗漏,并更接近实际的内存延迟,这就是ARM在这种情况下发布度量的基本原理。
我们还没有机会测试启用了大页面的竞品系统,但是AMD的EPYC 7601(LRDIMM DDR4 2666 19-19-19)可在芯片的高速缓存层次结构的末端通过类似于LMBench的测试来实现约73ns的延迟,而定制开发的延迟测试将TLB失败最小化后延迟约为57ns。Intel W-3175X(RDIMM DDR 2666 24-19-19)在相同测试下延迟分别为94ns和64ns。
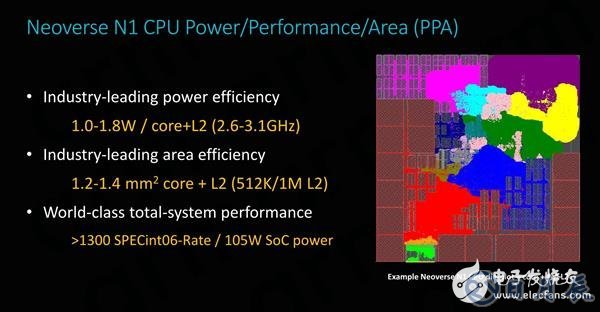
使用台积电7nm工艺制造的Neoverse N1芯片面积非常小,在使用512KB二级缓存时核心面积约为1.2平方毫米,与麒麟980所用Cortex A76的1.26平方毫米几乎相同,将L2缓存加倍到1MB后,核心面积也只有1.4平方毫米。
在频率范围方面,ARM的设想是在0.75V电压下达到2.6GHz,在1V电压下可实现3.1GHz。在这条频率曲线末端,提升44%的功耗只能得到19%频率和性能提高,因此大多数供应商都希望更接近功率曲线中更有效的部分。
不过从绝对数字来看,Neoverse N1的功耗只有1~1.8W,这为64核SoC提供了充足的空间,ARM对于64核Neoverse N1参考设计的总功率预算约为105W。
Neoverse N1超大规模参考设计
ARM提供Neoverse N1的完整参考设计,其中包含一组完全由ARM自己验证的IP。这套参考设计的目标是为供应商提供“甜点”配置选项,这样他们就可以用相对最少的努力来实现最优的性能。
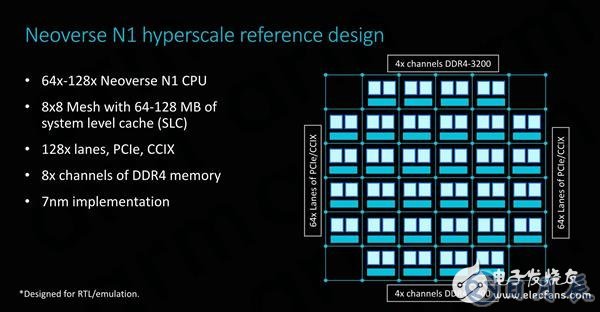
Neoverse N1的参考设计中可采用64或128核心配置,集成在具有64 MB或128MB 系统级缓存的CMN-600 mash网络中。I/O接口方面,128条PCI-E 4.0通道分别用于I/O和CCIX接口,可提供足够的I/O带宽。
在内存方面,ARM为其配置了8通道DDR4控制器,最高支持3200MHz。不过实际上,ARM已经放弃了自行研发内存控制器,因为大多数情况下客户会使用各自的内部设计,或者选择从其他第三方供应商(如Cadence或Synopsys)处选择方案。
对于目前的参考设计来说,ARM自己的DMC-520内存控制器仍然是最新的,且对于公司来说是一个很好理解的模块。不过在未来,像DDR5这样的较新的内存控制器也将不得不依赖于第三方IP。
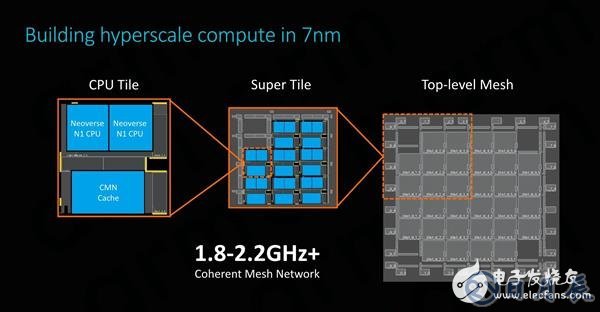
SoC的物理实现将使用便于设计的可复用分层构建块。每个CPU模块由两个Neoverse N1内核、一组系统级缓存,以及CMN的交叉点和本地节点的一部分组成。通过翻转和镜像来复制CPU模块,即可生成最终的SoC顶层网格。
在7nm工艺节点上,ARM的64核Neoverse N1参考设计搭配64MB高速缓存,芯片尺寸接近400平方毫米,可能略高于供应商想要的可制造性目标。为了缓解这种担忧,ARM同时提出了小芯片设计的想法,让多个小芯片通过CCIX链路进行通信,保证了必要的灵活性,供应商可自行决定如何设计解决方案。
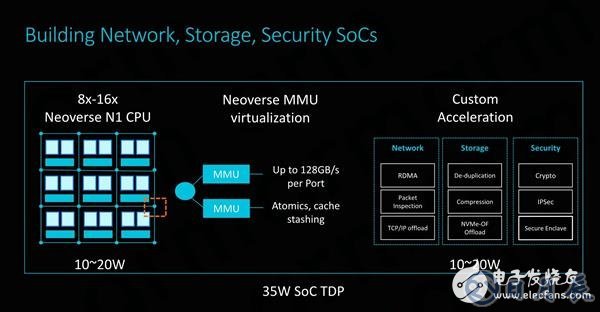
智能网卡的集成能力也是其设计和灵活性的一个重要方面,为了在大型系统中最大限度地提高计算能力,加速网络连接实际上是在尽可能密集且有效的形式因素下实现高吞吐量的关键。
CMN-600允许在其交叉点上设置从端口,通过高达128GB/s的高带宽总线与内存管理单元连接,可轻松外挂其他固定功能的硬件模块。
CCIX对ARM非常重要,因为它使其产品组合能够与第三方IP产品集成。 为外部IP模块启用高速缓存一致性是一个非常有吸引力的功能,因为它大大简化了供应商的软件设计。 基本上这意味着软件只是看到一个巨大的内存块,而非相干系统需要驱动程序和软件知道并跟踪内存的哪个部分是有效的,哪些不是。 在IP集成方面,ARM提供与CMN-600集成的CCIX一致网关,而另一方面,它是第三方IP提供商提供CCIX转换层的责任。

对ARM来说,CCIX非常重要,它可让其产品组合能够与第三方IP产品集成。为外部IP块启用缓存一致性是一个非常有吸引力的特性,可大大简化供应商的软件设计,不再需要系统、驱动和软件跟踪哪些是有效内存。在IP集成方面,ARM提供了与CMN-600集成的CCIX相干网关,而第三方IP提供商则提供CCIX翻译层。
在芯片的逻辑设计中,供应商还必须设计一套健壮的配电网络,以支撑实际使用情况中各种突发且严苛的电能需求。这对许多供应商而言都是一个非常头疼的问题,因为设计需要复杂的模型,且在大多数情况下,配电网络需要过度设计以提供稳定性保证,这反过来又增加了实施的复杂性和成本。

ARM旨在通过以专用微控制器的形式提供极细粒度的DVFS(动态电压频率调整)机制来缓解这些问题。控制器访问CPU核心内部的详细活动监视单元,查看实际有多少晶体管正在积极工作,并将此信息反馈给系统控制器以更改DVFS状态。这使供应商能够将其配电网络设计为更保守的容差,从而节省实施成本。
性能预测
关于性能和效率的讨论,必然需要用具体的数字来衡量。在ARM公布Neoverse N1时,大多数性能数据都是相对于Cortex A72的改进,这并没有将Neoverse N1真正置于竞争格局中最相关的数据点。Cortex A72是一款2015年推出的架构,两款产品之间有着3~4年的时间跨度。
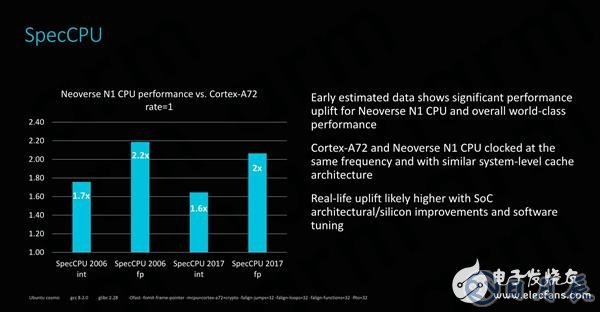
与相同频率且同样配有系统级缓存的Cortex A72平台相比,全新的Neoverse N1平台直接以碾压的姿态获得完胜。在SPEC的单线程测试中,Neoverse N1的整数运算PPC(每时钟性能)和绝对性能相比Cortex A72增长了60%~70%,浮点运算性能则更令人印象深刻,增幅高达100%~120%。且鉴于Neoverse N1还有许多其他SoC级别的改进及软件优化,实际的性能表现将会更高。
与现有解决方案相比,ARM再次迭代了非常大幅的性能演进,在向量工作负载中实现了超过2倍的性能提升。自然,Neoverse N1支持ARMv8.2指令集也意味着它支持8位点积和FP16半精度指令,这些指令特别适合机器学习工作负载,实现了比前一个平台近5倍的性能提升。

对于运行速度约为2.6GHz的64核Neoverse N1超大规模参考设计,在105瓦TDP下,其SPECint2006单线程得分约为37,而多线程得分预计约为1310。
不过这一性能不是在实际运行的产品上测出的,而是在ARM的服务器群上使用RTL模拟环境中估算出来的。

Neoverse N1的单线程得分,明显高于在同源的Cortex A76上测量的26分,撇开软件和编译器的考虑不提,造成42%性能差异的原因之一可能是Neoverse N1拥有更好的内存和缓存系统,整个系统带宽比Cortex A76这种移动SoC高6倍,在单线程工作负载中,线程可以完全访问64MB系统级缓存,这比Cortex A76设计的L3缓存大16倍。
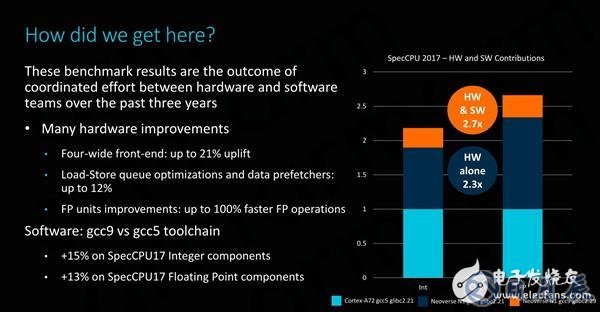
ARM强调,在改善生态系统性能的众多努力中,除了提供更好的硬件之外,还需要提供更好的软件。在过去的几年里,ARM投入了大量精力来改进开源工具和编译器,比如将最新版GCC9与旧版的GCC5进行比较,其整数和浮点工作负载的性能提高了13~15%,且这些优化是面向实际用例的改进,而不是旨在提升SPEC跑分的针对性的改变。
就单线程性能而言,Neoverse N1看起来非常出色,它以很大的优势击败了目前性能最佳的ARM服务器CPU,即Cavium的ThunderX2。
既然是面向服务器领域的产品,免不了要与老牌供应商Intel和AMD进行对比,在Intel和AMD最新的、也是最好的Xeon W-3172X以及EPYC 7601上,同样使用GCC8编译一组二进制文件进行。
Intel的Xeon W-3172X很难说是最具代表性的超大规模CPU,但它4.5GHz的单核睿频频率可提供多核CPU中最强的单线程性能。 AMD的EPYC 7601则是一个更有代表性的数据点,其3.2GHz的频率和Neoverse N1很有的比,实际成绩来看也确实如此。

再来看SPECrate2006的多线程测试,这是所有平台的最佳扩展场景,没有序列化或线程间通信,测试套件只是并行运行多个进程。
从ARM给出的模拟测试结果来看,64核的Neoverse N1以105瓦的TPD实现了极高的性能和效率,x86解决方案甚至很难能够竞争。

虽然测试比较的是64核ARM平台与32/28核x86平台,貌似使用AMD即将推出的64核Rome处理器才更公平,但从数据来看,即使AMD的64核处理器能实现目前双倍的性能,其TDP也不太可能降低到Neoverse N1这样105 瓦的水平(EPYC 7601的TDP 是180瓦)。
总结
Neoverse N1看起来是一款优秀的架构,它保持了ARM一贯领先的电源效率,实现了峰值计算性能和总体吞吐量之间的最佳平衡。
ARM对Neoverse N1及其最终的继任者抱有很高的期望,希望从Intel等供应商中抢走x86处理器根深蒂固的市场份额。ARM正在尽最大努力,虽然Neoverse N1不会成为旗舰x86的核心竞争对手,但在可以轻松扩展到更多核心的工作负载中,它会构成重大威胁。
当然,在实际硬件产品出现之前,我们还不能下任何定论,但ARM此前对Cortex A76的性能预测非常符合实际设备上的测量结果,因此我们有理由给予Neoverse N1的性能预测以信任,实现预测中的性能肯定是有希望的。
尽管新的硬件IP令人印象深刻,但同样重要的是ARM在加强ARM软件生态系统方面的努力。与不同行业的硬件和软件合作伙伴合作,试图促进软件堆栈和与ARM的互操作性,这不仅有利于使用ARM自己的硬件IP的供应商,而且有利于选择使用自己的定制CPU和SoC设计的供应商。同样,那些试图改进和加强自己产品的供应商,也将反过来加强ARM的生态系统。本质上,这是许多公司之间的集体努力,未来将继续获得动力。

可以看出,ARM正非常认真地对待基础设施建设,过去的一年对于ARM生态系统来说是革命性的,我们第一次看到了ARM厂商平台与Intel和AMD等主流厂商竞争。虽然ARM没有透露谁将首先使用Neoverse N1平台的信息,但ARM正无可辩驳地成为行业主流。
据传Neoverse N1将在未来12~18个月内进行商业部署,这将是ARM的关键时刻。如果一切进展顺利,ARM和合作伙伴实现了承诺的改进,未来1~2年里,服务器行业必将迎来一次重大转变。

