131 1300 0010
据国外媒体报道,英特尔公司高管近日表示,他们会在明年年底量产 10nm 的处理器,对 7nm 工艺的研发进程,他们也感到满意。
在处理器制造工艺方面,台积电去年量产了 10nm 工艺,更先进的 7nm 工艺也已在今年量产,而芯片巨头因特尔在 10nm 和 7nm 工艺方面则是遇到一些麻烦,原计划在 2016 年下半年就大规模量产的 10nm 处理器,至今依旧未能实现,已延期多年。

处理器工艺的延期也给英特尔的业务和产品也带来的一定的影响,其在去年二季度就被三星挤下了全球第一大芯片厂商的宝座,自 1993 年以来首次在芯片营收方面被其他厂商超过。
但好消息是英特尔延期多年的 10nm 处理器会在明年大规模量产,对 7nm 工艺的研发,他们也感到满意。

英特尔在明年量产 10nm 处理器的消息,是由其首席工程官兼技术、系统架构和客户部门总裁默西· 伦杜琴塔拉 ( Murthy Renduchintala ) ,近日在第39 届纳斯达克投资者大会上透露的。

在 10nm 处理器方面,默西 · 伦杜琴塔拉确认英特尔计划在明年年底大规模量产,首先量产的将是客户端的处理器,数据中心需要的产品会在随后推出。
虽然英特尔的 10nm 处理器已延期多年,但英特尔并未因此而调整相应的技术指标以便提前推出,默西· 伦杜琴塔拉就表示,他们在 2014 年为 10nm 处理器所设定的能耗、性能、晶体管密度等各项指标仍然不变。

如果芯片工艺是由同一个团队负责循序渐进研发,一旦 10nm 延期,其更先进的 7nm 工艺也就会受到影响,但英特尔在这方面可能并不会有太大的麻烦。
默西 · 伦杜琴塔拉在大会上就表示,更先进的 7nm 工艺是由一个独立的团队负责,他们对 7nm 工艺的进展也非常满意,他们将汲取在 10nm 工艺上的教训,他们打算按内部最初的计划量产 7nm 工艺。
昨天,在英特尔“架构日”活动中,英特尔高管、架构师和院士们展示了下一代技术,其中宣布2020年独显构架名称——“Intel Xe”。

英特尔宣布他们即将推出的2020 GPU架构代号为Intel Xe(或Xe)。这个名字取代传闻中的“Arctic Sound”或“Gen12”。值得注意的是,这是架构的名称,实际产品将具有不同的名称。
但是关于构架本身并没有透露太多细节。在“构架日”期间,英特尔表示新的Xe构架将采用10nm制造技术。英特尔进一步确认Xe架构将涵盖整个市场,包括集成,数据中心和消费产品。

英特尔架构日上发布的重点内容包括:
业界首创的逻辑芯片3D堆叠:英特尔展示了名为“Foveros”的全新3D封装技术,该技术首次引入了3D堆叠的优势,可实现在逻辑芯片上堆叠逻辑芯片。
Foveros为整合高性能、高密度和低功耗硅工艺技术的器件和系统铺平了道路。Foveros有望首次将晶片的堆叠从传统的无源中间互连层和堆叠存储芯片扩展到高性能逻辑芯片,如CPU、图形和人工智能处理器。
该技术提供了极大的灵活性,因为设计人员可在新的产品形态中“混搭”不同的技术专利模块与各种存储芯片和I/O配置。并使得产品能够分解成更小的“芯片组合”,其中I/O、SRAM和电源传输电路可以集成在基础晶片中,而高性能逻辑“芯片组合”则堆叠在顶部。

英特尔预计将从2019年下半年开始推出一系列采用Foveros技术的产品。首款Foveros产品将整合高性能10nm计算堆叠“芯片组合”和低功耗22FFL基础晶片。它将在小巧的产品形态中实现世界一流的性能与功耗效率。
继2018年英特尔推出突破性的嵌入式多芯片互连桥接(EMIB)2D封装技术之后,Foveros将成为下一个技术飞跃。
全新Sunny Cove CPU架构:英特尔推出了下一代CPU微架构Sunny Cove,旨在提高通用计算任务下每时钟计算性能和降低功耗,并包含了可加速人工智能和加密等专用计算任务的新功能。明年晚些时候,Sunny Cove将成为英特尔下一代服务器(英特尔®至强®)和客户端(英特尔®酷睿™)处理器的基础架构。

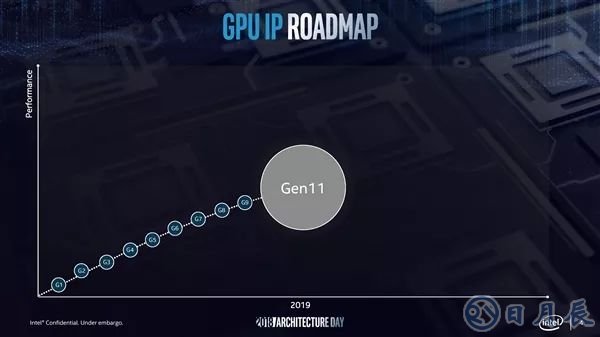
英特尔推出全新的第11代集成图形卡,配备64个增强型执行单元,比此前的英特尔第9代图形卡(24个EU)多出一倍,旨在打破每秒1万亿浮点运算次数(1 TFLOPS)的壁垒。从2019年开始,新的集成图形卡将与10纳米处理器一起交付。
与英特尔第9代图形卡相比,新的集成图形卡架构有望将每时钟计算性能提高一倍。凭借高于每秒1万亿浮点运算次数的性能,该架构旨在提高游戏的可玩性。与英特尔第9代图形卡相比,英特尔在此次活动上展示的第11代图形卡几乎将一款流行的照片识别应用程序的性能提高了一倍。第11代图形卡预计还将采用业界领先的媒体编码器和解码器,在有限的功耗配额下支持4K视频流和8K内容创作。第11代图形卡还将采用英特尔®自适应同步技术,为游戏提供流畅的帧速率。

英特尔还重申了在2020年推出独立图形处理器的计划。
推出“One API”项目,以简化跨CPU、GPU、FPGA、人工智能和其它加速器的各种计算引擎的编程。该项目包括一个全面、统一的开发工具组合,以将软件匹配到能最大程度加速软件代码的硬件上。公开发行版本预计将于2019年发布。

英特尔宣布推出深度学习参考堆栈(Deep Learning Reference Stack),这是一个集成、高性能的开源堆栈,基于英特尔®至强®可扩展平台进行了优化。该开源社区版本旨在确保人工智能开发者可以轻松访问英特尔平台的所有特性和功能。深度学习参考堆栈经过高度调优,专为云原生环境而构建。该版本可以降低集成多个软件组件所带来的复杂性,帮助开发人员快速进行原型开发,同时让用户有足够的灵活度打造定制化的解决方案。

