131 1300 0010
web的最大优势之一是其开放性和分布式本质。这也是一大挑战:数百万站点,数千项主题,人们如何浏览内容并发现新的可信赖信息源?
Feedly对这一挑战的解决方案是使用数据科学组织所有这些信息源,并帮助人们浏览主题。
本文介绍了[Feedly新的发现体验]背后的一些技术,以及我从这一项目中学习到的经验。
从用户生成数据中学习主题
根据用户加入新站点或博客时所属的分类(数据经过匿名化处理),可以自动创建新的英语主题分类。
所以,如果你是在“tech”(技术)下加入The Verge和Engadget的45000人之一,那么你帮助创建了“tech”主题。
不过,这样的主题列表仍然存在一些问题,主要是重复主题和“垃圾主题”。
想要理解我是如何训练模型识别主题的,可以想像一个矩阵或者表格,其中有关于主题和信息源的数据。
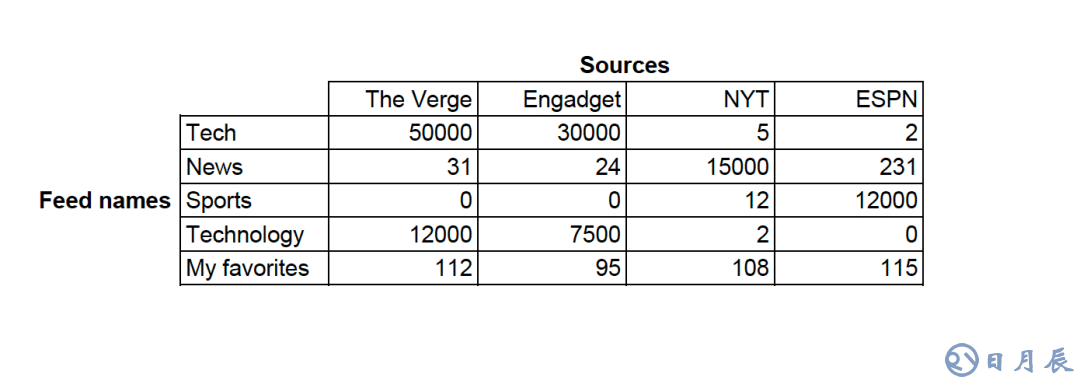
你注意到了上表第六行的“My favorites”(我的最爱)主题了没有?这是一个极好的垃圾主题的例子,因为它不具有描述性。你可能也注意到了“tech”和“techonolgy”这一对重复主题。如果我们将矩阵扩展至10000+主题和100000+信息源,我们会看到很多这样的垃圾主题和重复主题。
所以我们如何摆脱这些垃圾主题和重复主题呢?这正是数据清洗的价值所在。
在上表中,每行有一个数字数组,也称为向量。所有数字同构的行意味着垃圾主题,而特定站点在行中显示为峰值的是好主题。
一图胜千言:
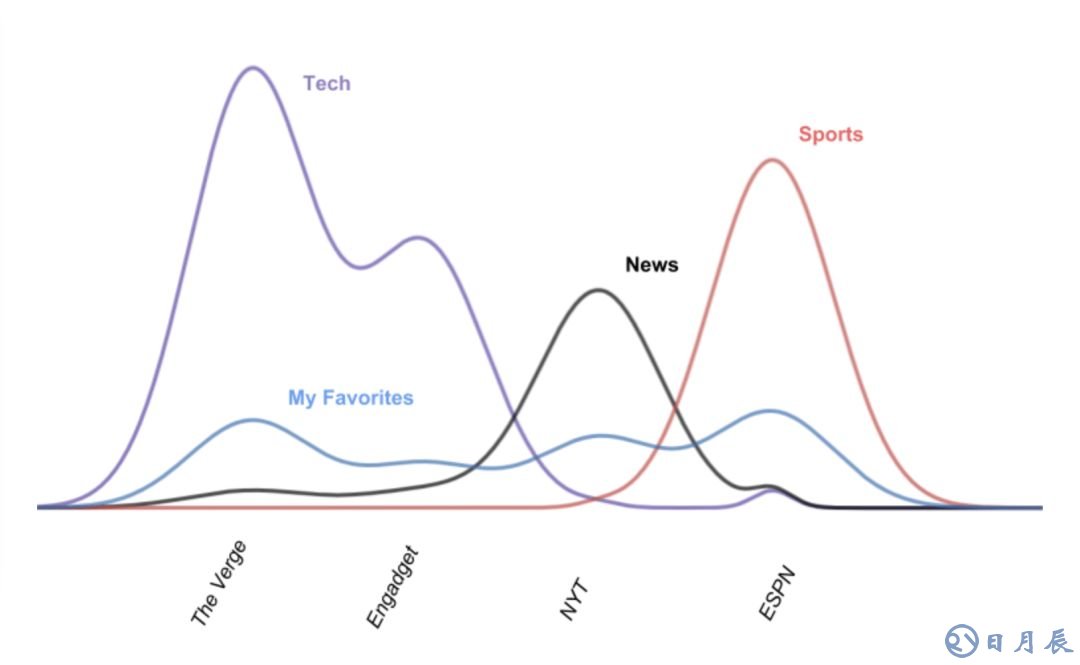
我们可以通过测量相应图形的尖峰来检测垃圾主题。从向量性质的角度来说,我们可以,比方说,测量最大数字和非零值数字的比值。
类似地,下面的图形显示了重复主题:
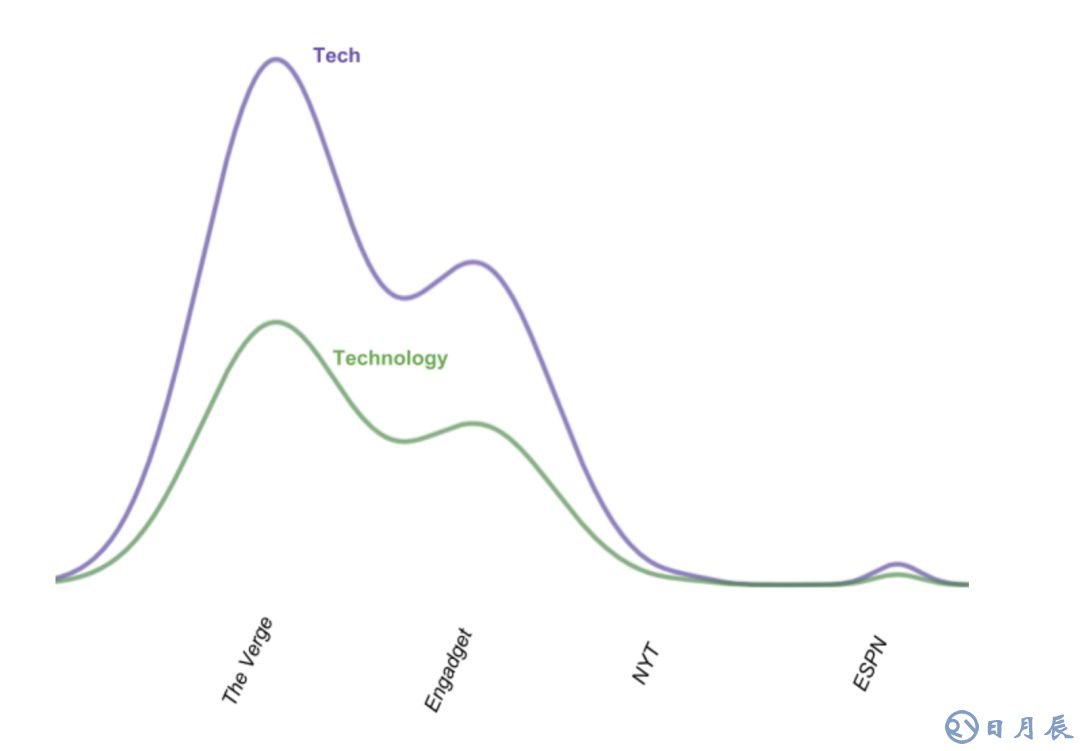
我们同样根据向量的性质检测这些重复主题。在我们的例子中,“Tech”向量的分量[50000, 30000, 5, 2]和“Technology”的[12000, 7500, 2, 0]在归一化(将绝对数字转换为百分比)后非常相似。我使用JS散度得出两个向量的相似度。
一旦侦测出了相似向量,我们可以在系统中安全地合并两者,并将搜索“technology”的用户重定向至“tech”。
感谢使用Feedly的英语读者的巨大社区,我们得以将所有数据转换为一个整洁、去重的包含超过2500良好主题的列表。
我们很高兴地报告,我们的分类足够深入,包含“真菌学”这样的主题!
链接的强度与同属两个主题的信息源数量成正比
主题树:创建层次结构
既然我们的信息源已经有了丰富的主题标签,下一个挑战是引入连接相关主题的更好的组织系统。
有些主题是通用的(“tech”),而另一些则要专门一些(“iPad”)。“iPad”属于“Apple”的子主题,“Apple”又是“Tech”的子主题,像这样的主题层次结构的内部表示,有助于计算推荐。
我们使用模式匹配创建这样的层次结构。下图显示了三个主题(左侧)和与这些主题相关的信息源(右侧)的连接。线越粗,将信息源置于这一主题下的用户就越多。
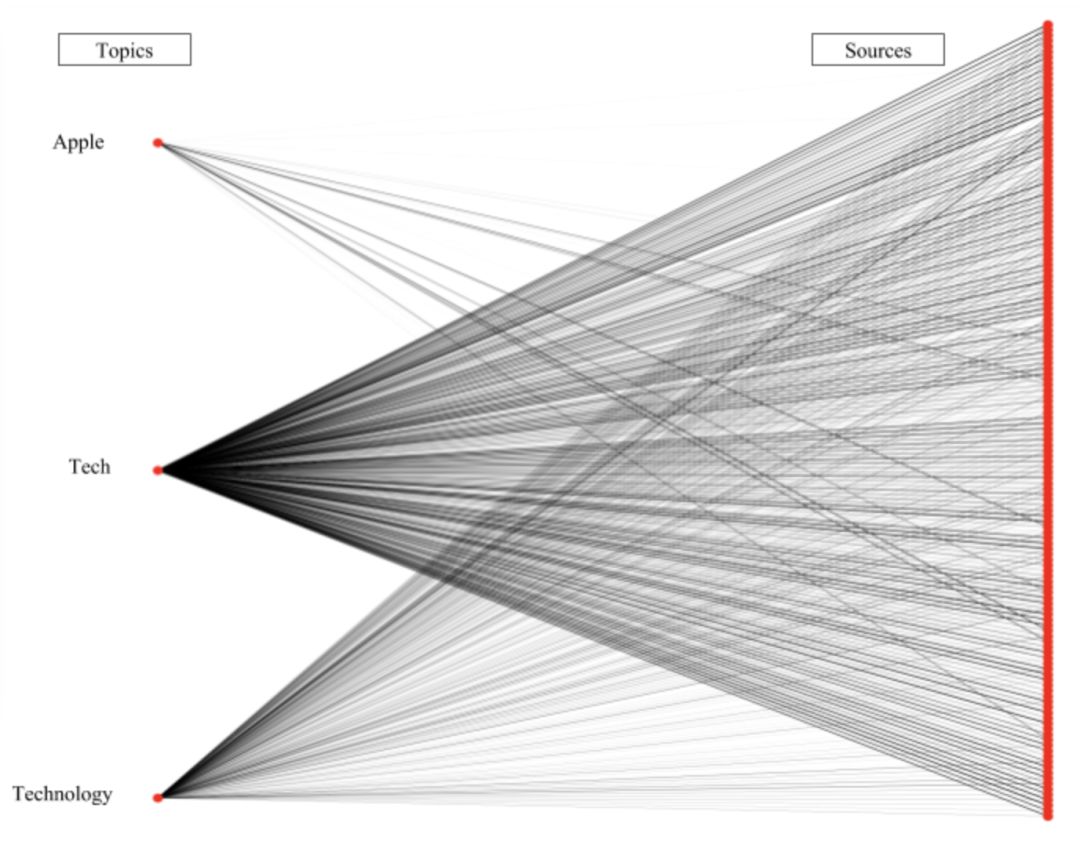
“Apple”连接“tech”主题信息源的一个子集,所以“Apple”是“tech”的子主题
上面的模式也确认了人们以大致相同的方式使用“tech”和“technology”。“technology”的线要细一点,因为人们较少使用这一术语。不过这两个主题是重复的。同时,“Apple”看起来是“tech”的子主题:它连接了更少的信息源,而且它的连接同时也和“tech”相关。
基于这些模式,我们可以构建所有主题和子主题的树形结构。

现在,如果你访问Feedly的Discover(发现)页面,你会找到一个特色主题列表。点击任意主题即可开始浏览。相关主题有助于你进一步深入层次结构。
排列每个主题的推荐信息源
创建主题并组织为层次结构后,我们仍然需要决定推荐哪些信息源,以什么顺序推荐。我们想要根据以下三个标准进行优化:
相关性 —— 用户添加信息源至该主题与其他主题的比例
关注数 —— 多少用户连接了这一信息源
粘度 —— 质量和关注的代理
前两个标准很是直截了当。人们期望看到和他们浏览的主题相关的流行网站,同时常常需要折衷这两个测度。
第三个标准更加主观。它应该反映网站的质量,独立于阅读该站点的用户绝对数量。事实上,我们相信,一些小众站点可能读者较少,但内容更好。
“信息源之战”试验
为了计算粘度评分,我们在Feedly社区中运行了一项试验。我们选择了一些和“tech”主题相关的信息源,并让用户投票更喜欢哪些信息源。
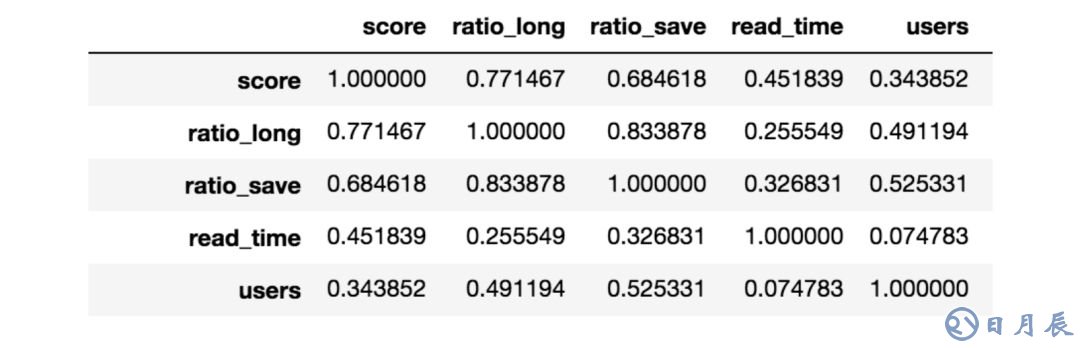
我们在一周内收集了25000张票,生成了这些站点的排名。我们寻找和用户喜欢程度最相关的特征。
例如,在下表中,我们展示了信息源得分和阅读该信息源的平均时间之间的关系(“read_time”,阅读时间,相关性大致等于0.45)。相关性是正的,这意味着评分越高,人们花在该信息源上的时间大概就越长。这里例子中的其他特征同样显示了正相关性,因为它们都是好信息源的指标。我们的方法让我们得以选出和投票结果最相关的特征。接着我们就可以加权组合这些特征,以稍微提升最好的那些信息源的排名。
感谢所有为“信息源之战”试验投票的人。在Discover页面浏览特色主题,或者搜索你最喜欢的主题的时候,都用到了这次试验的结果。
生成“你可能也喜欢”信息源和更多“相关主题”
相关主题不仅包括上面提到的子主题(取自层次结构),还包括基于item2vec协同过滤得到的主题。
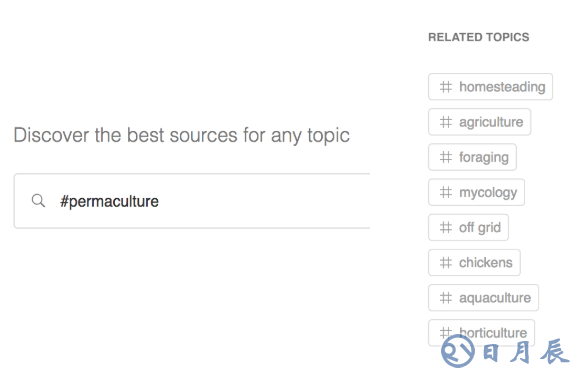
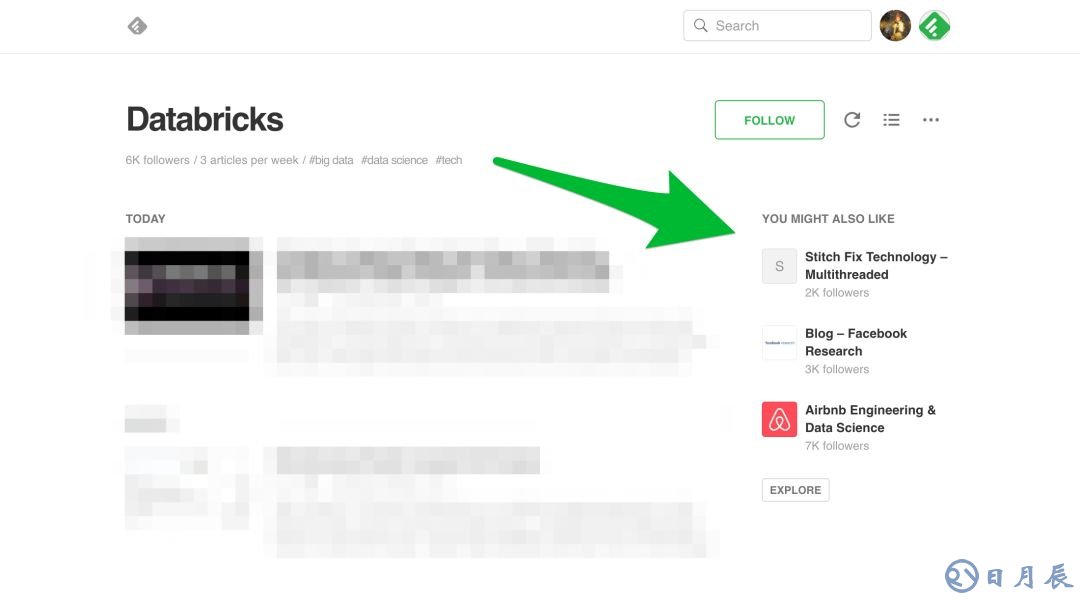
我们同样基于item2vec技术,根据你已经关注的信息源,推荐“你可能也喜欢”(You Might Also Like)的信息源。
结语
十分感谢Feedly社区为发现项目所做的直接和间接贡献。祝探索愉快!

